Most deep neural networks are trained once and then evaluated.
In contrast, continual learning mimics how humans continually learn new knowledge
throughout their lifespan. Most continual learning research has focused on mitigating a phenomenon called
catastrophic forgetting, in which neural networks forget past information. Despite making remarkable progress
toward alleviating catastrophic forgetting, existing algorithms remain compute-intensive and ill-suited for
many resource-constrained real-world applications such as edge devices, mobile phones, robots, AR/VR and virtual assistants.
For continual learning to make a real-world impact, continual learning systems need to provide computational efficiency and
rival traditional offline learning systems retrained from scratch when dataset grows in size.
Towards that goal, we propose a novel online continual learning algorithm named
SIESTA
(Sleep Integration
for Episodic
STreAming).
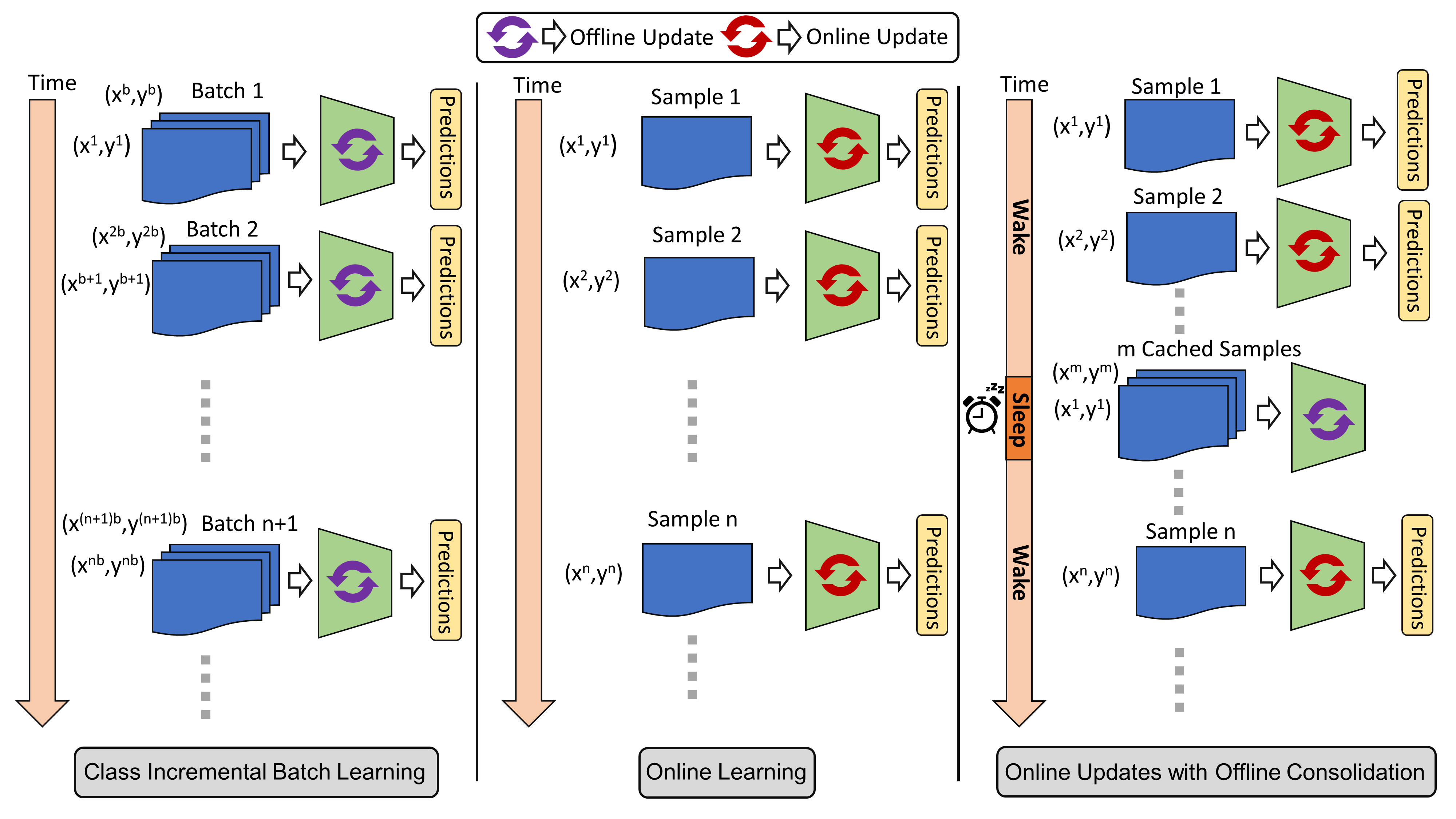
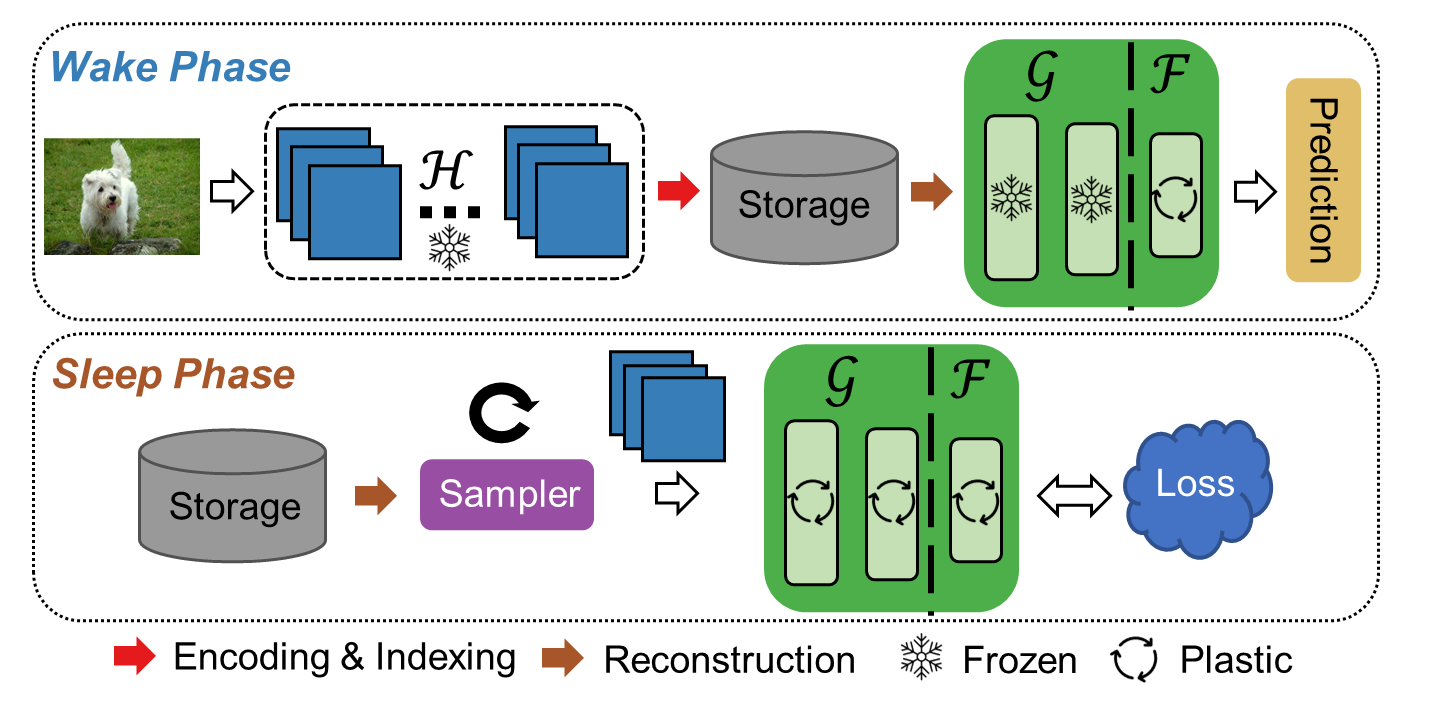
SIESTA uses a wake/sleep framework for training, which is
well aligned to the needs of on-device learning.
The major goal of SIESTA is to advance compute efficient continual learning so that DNNs can
be updated efficiently using far less time and energy. The principal
innovations of SIESTA are: [1] rapid online updates using a rehearsal-free, backpropagation-free,
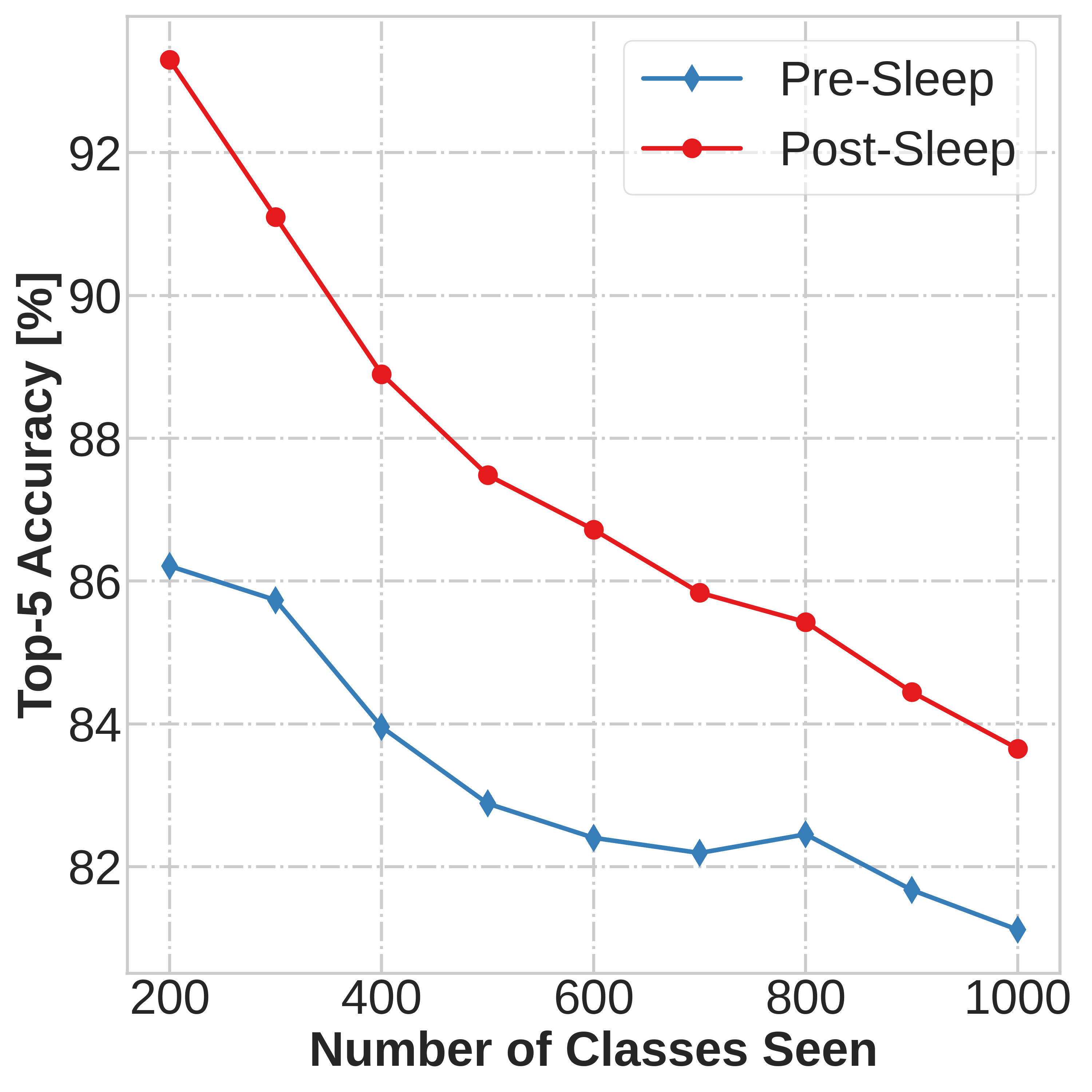
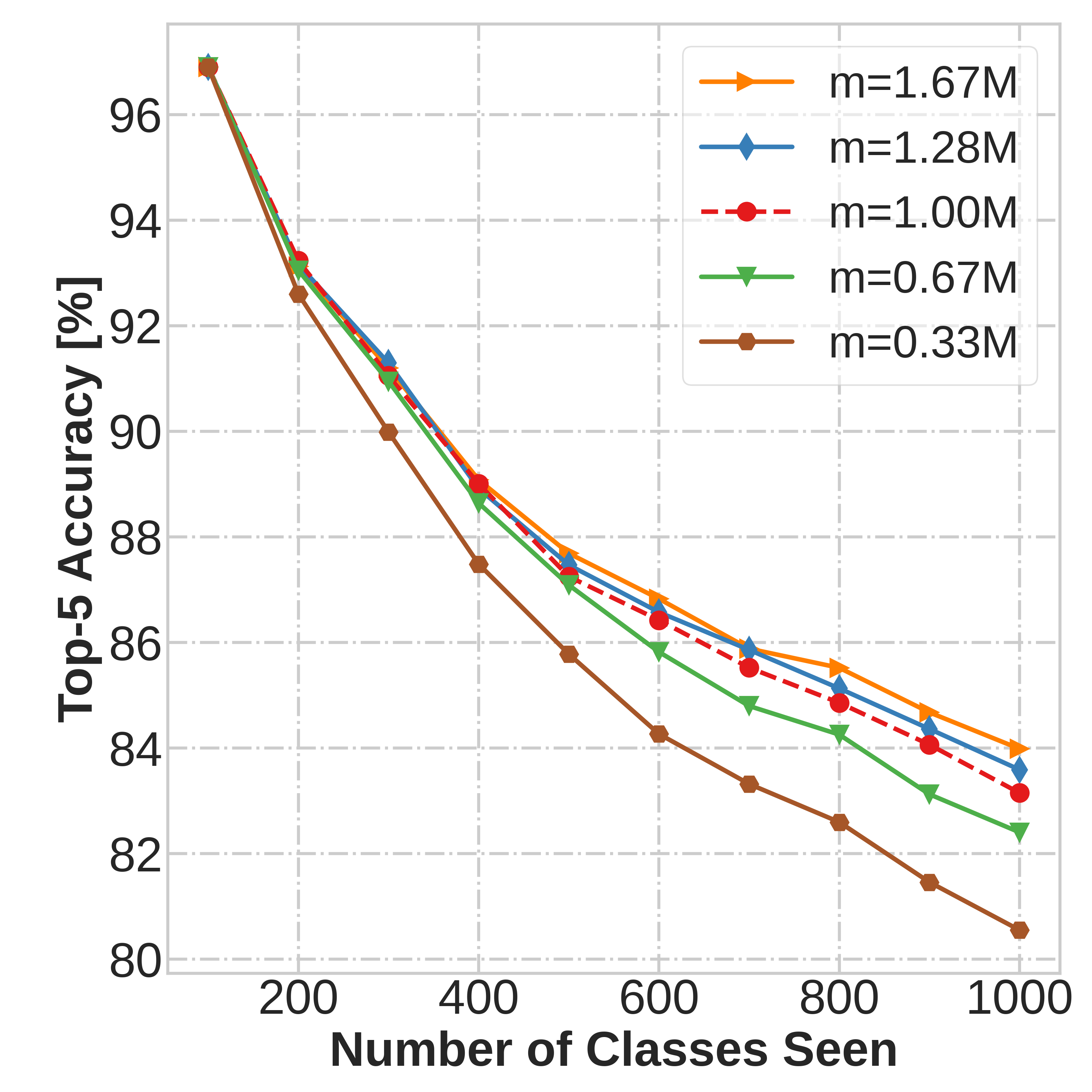
and data-driven network update rule during its wake phase, and [2] expedited memory consolidation
using a compute-restricted rehearsal policy during its sleep phase.
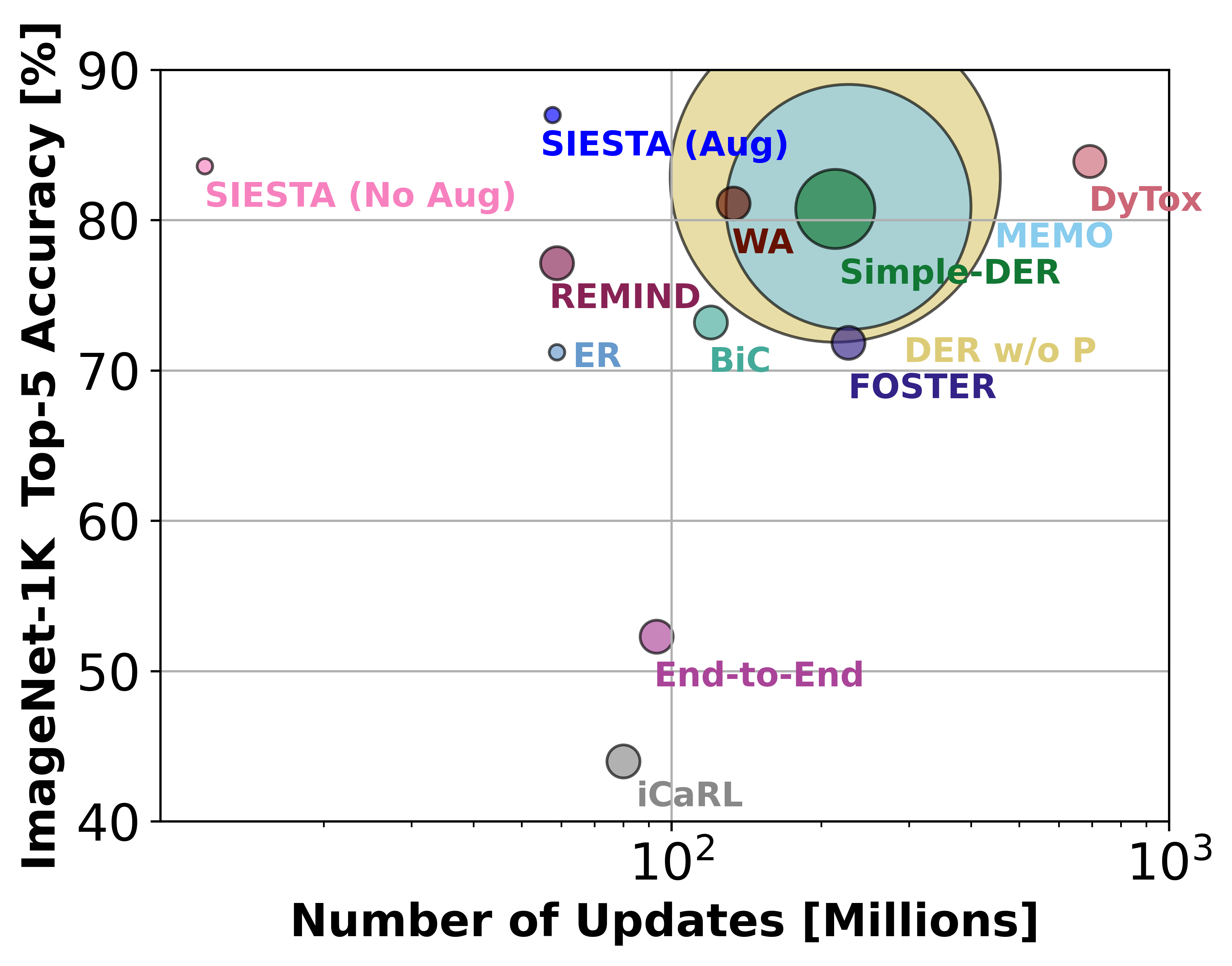
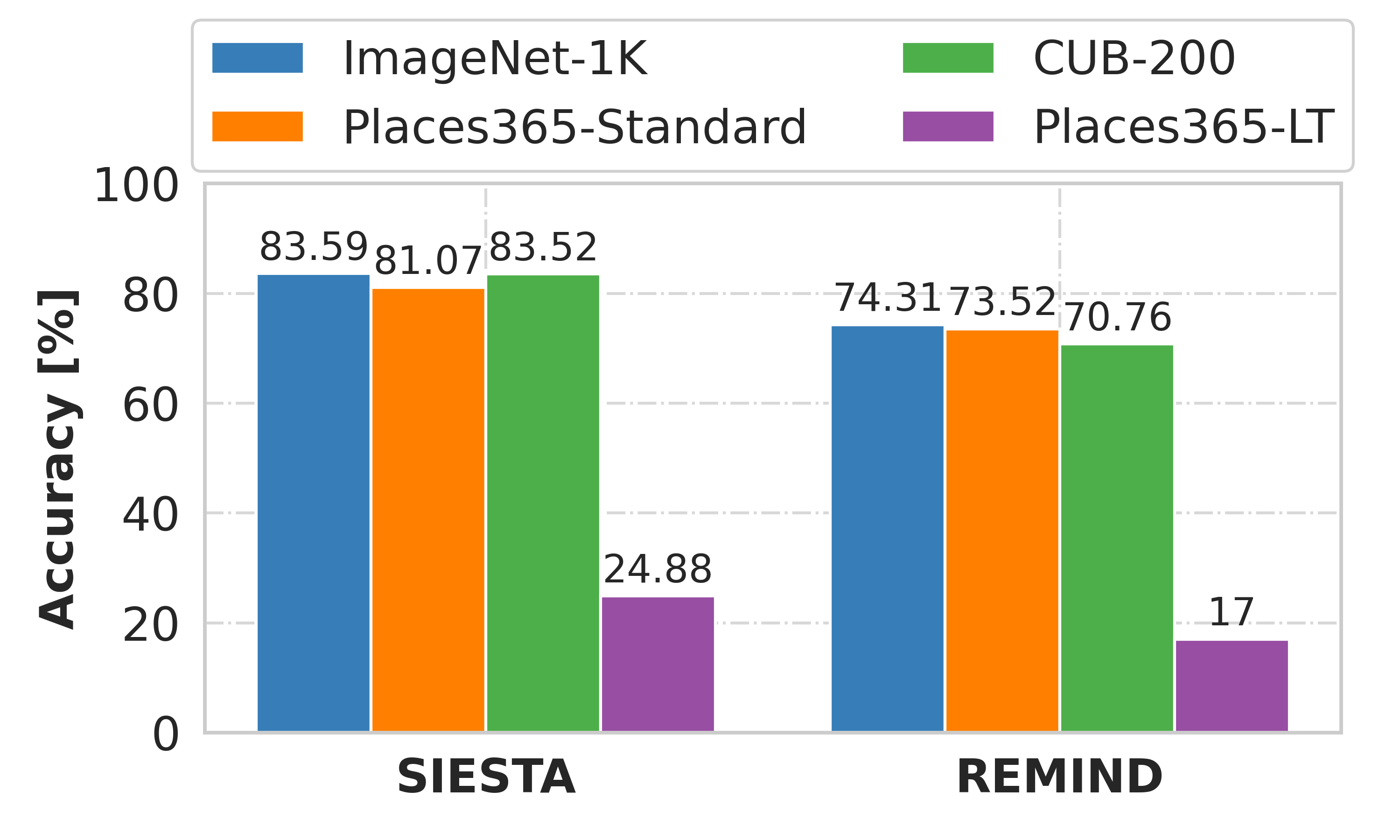
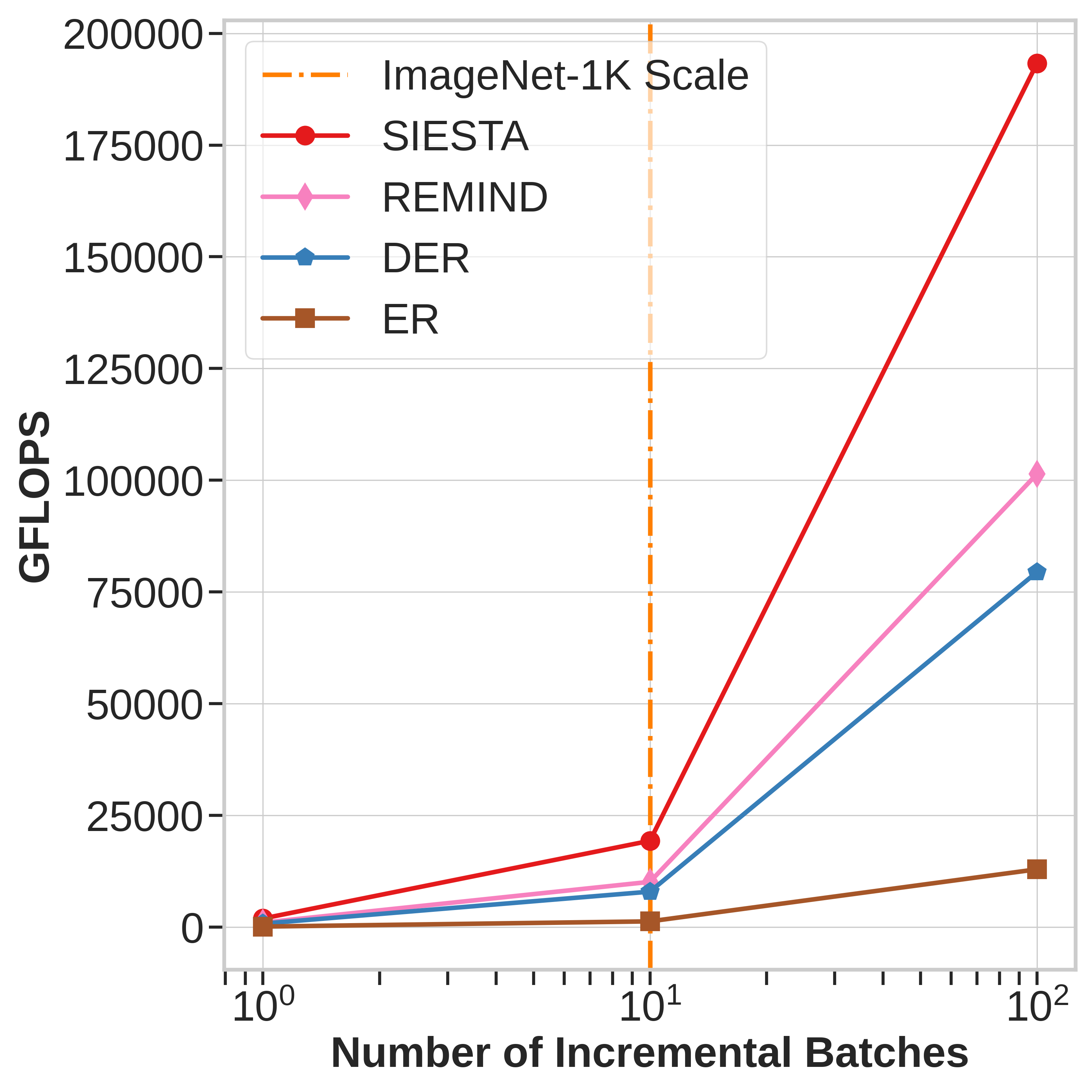
SIESTA is far more computationally efficient than existing
methods, enabling continual learning on ImageNet-1K in under 2 hours on a single GPU; moreover, in the
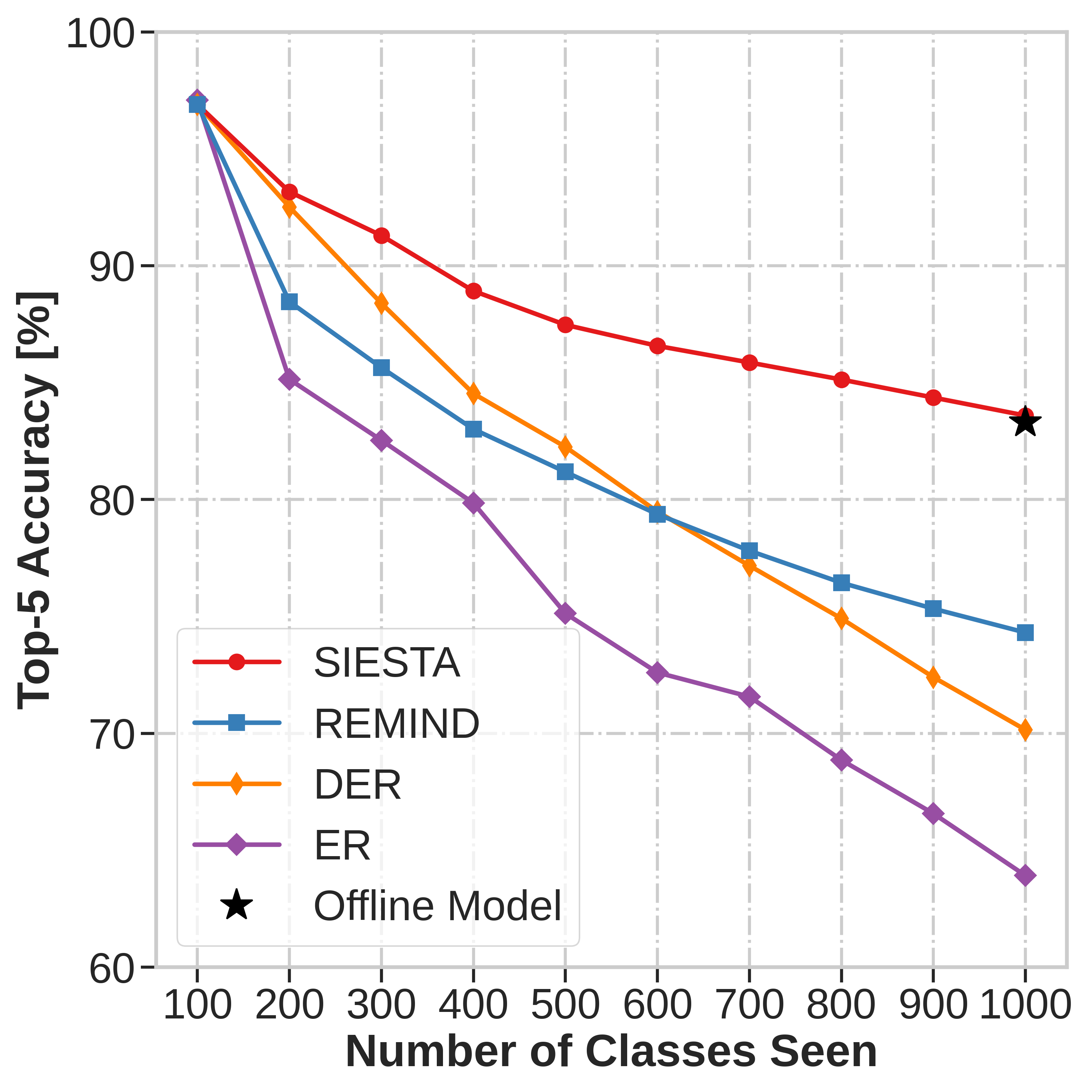
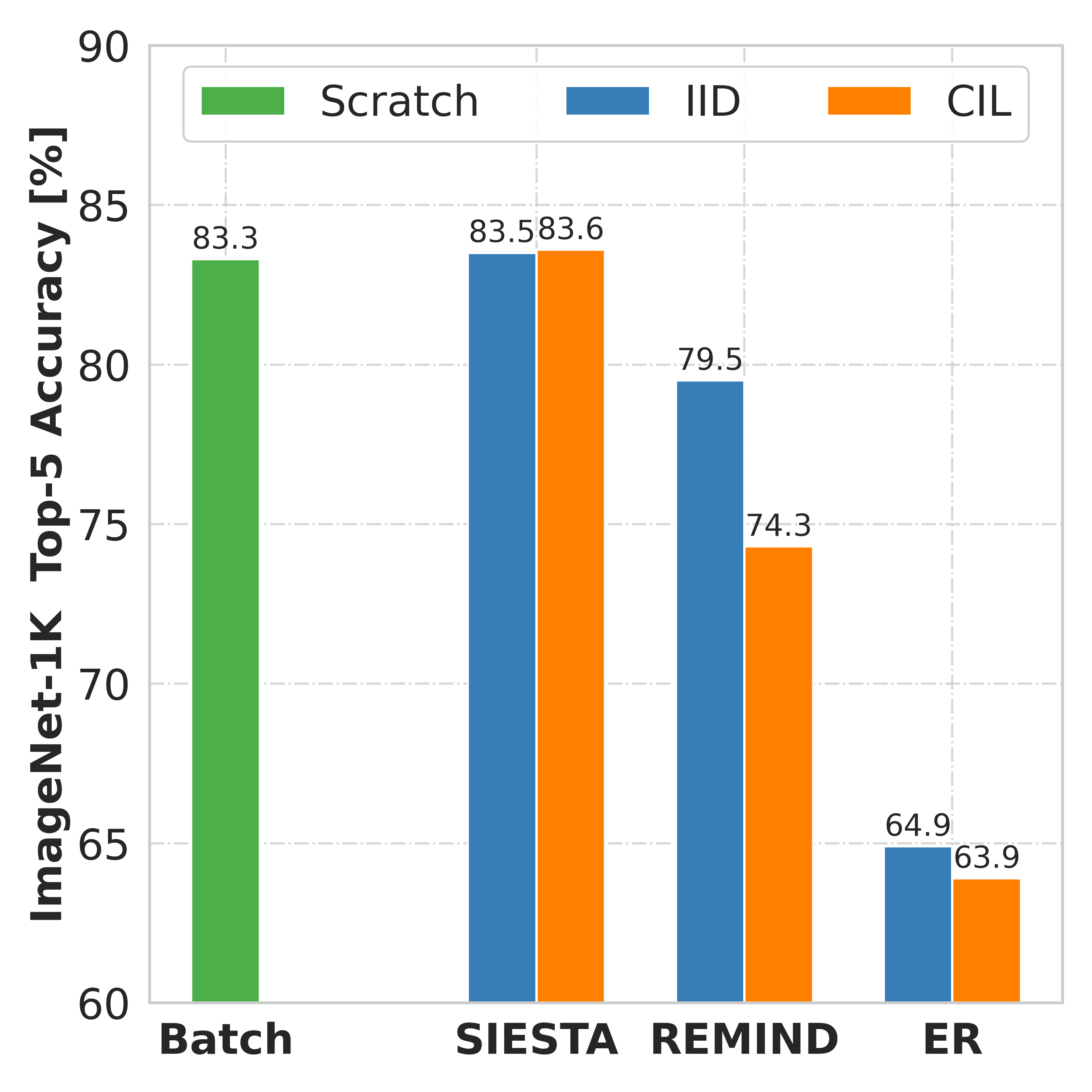
augmentation-free setting it matches the performance of the offline learner, a milestone critical to driving
adoption of continual learning in real-world applications.