ICML 2025: Controlling Neural Collapse Enhances Out-of-Distribution Detection and Transfer Learning
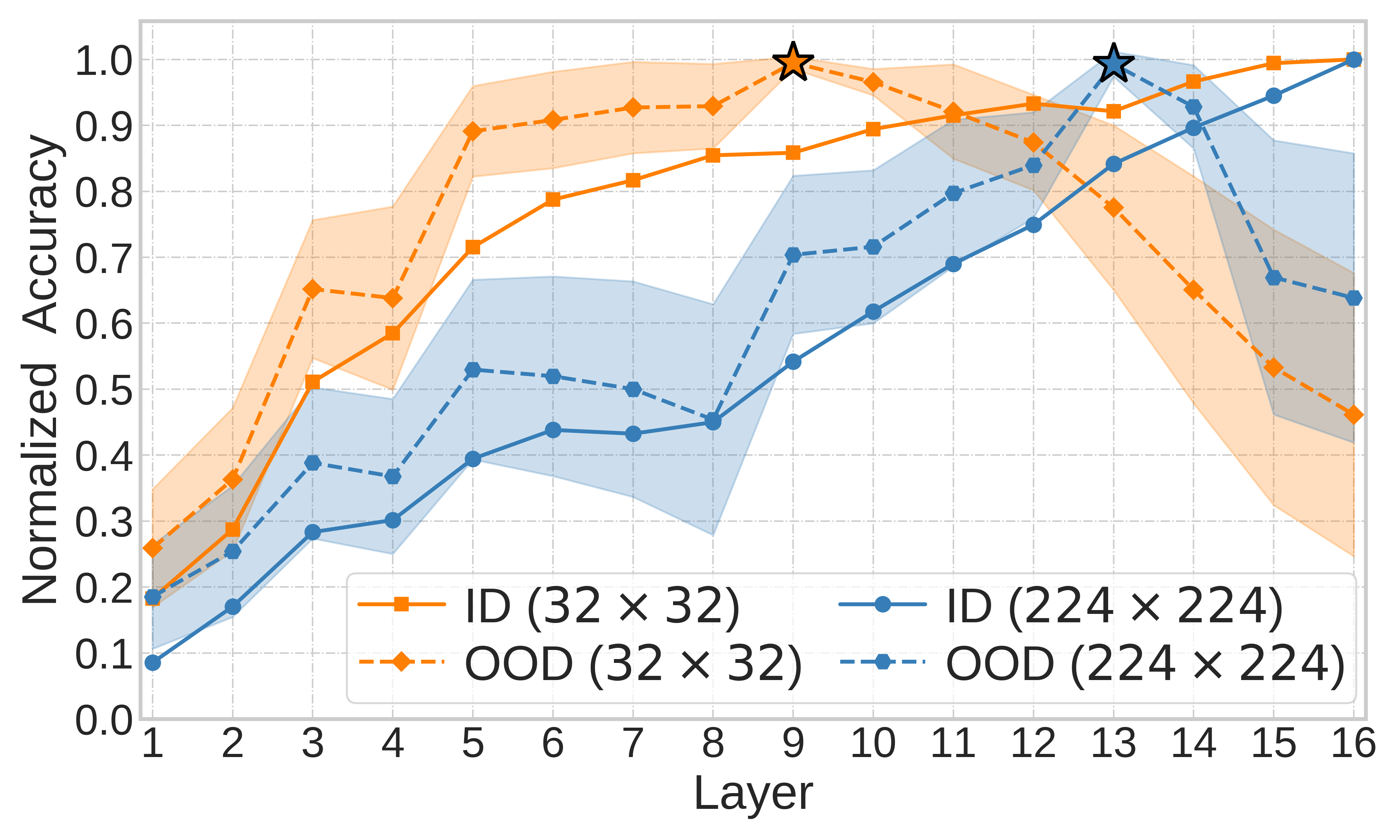
Out-of-distribution (OOD) detection and OOD generalization are widely studied in deep learning, yet their relationship remains poorly understood. We empirically show that the degree of Neural Collapse (NC) in a network layer is inversely related with these objectives: stronger NC improves OOD detection but hurts generalization, while weaker NC does the opposite. This trade-off suggests that a single feature space cannot simultaneously achieve both tasks. To address this, we develop a theoretical framework linking NC to these objectives and propose a method to control NC across layers using entropy regularization for OOD generalization and a fixed Simplex ETF projector for OOD detection.